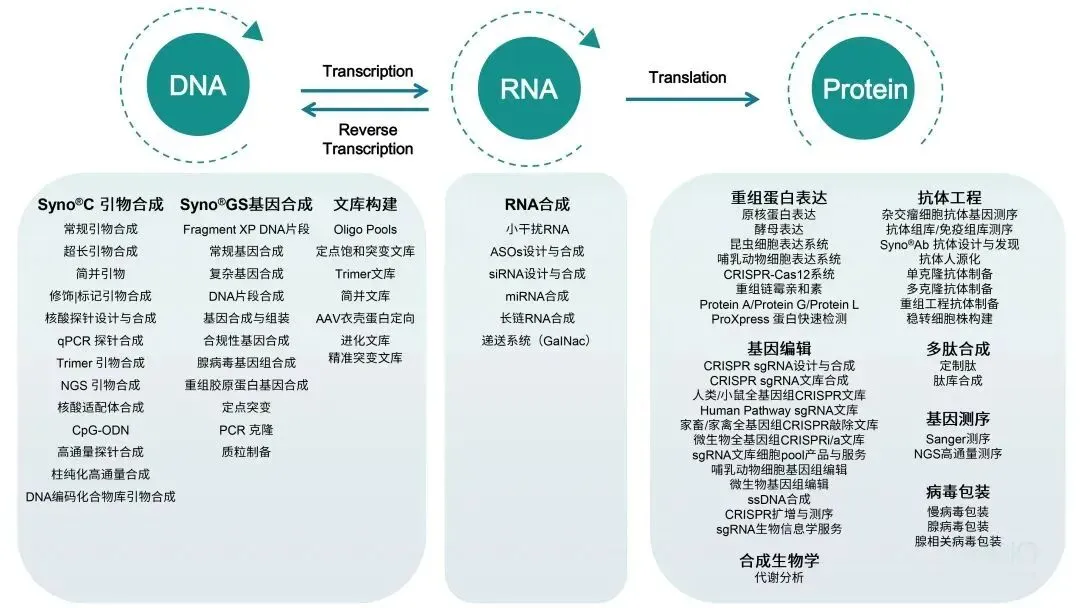
Syno®C 引物合成
Syno®C 引物合成 RNA合成
RNA合成 mRNA合成
mRNA合成 Syno®GS 基因合成
Syno®GS 基因合成 载体构建
载体构建 高通量及DNA文库构建
高通量及DNA文库构建 CRISPR基因编辑平台
CRISPR基因编辑平台 病毒包装
病毒包装 基因测序与组学分析
基因测序与组学分析 重组蛋白表达平台
重组蛋白表达平台 抗体工程平台
抗体工程平台 多肽服务
多肽服务 生物信息学分析与设计
生物信息学分析与设计 CRISPR文库
CRISPR文库 合成生物学产品
合成生物学产品 ProXpress蛋白快速检测
ProXpress蛋白快速检测 CRISPR 质粒
CRISPR 质粒
从设计到筛选,Trimer如何破解高复杂度文库难题

引言

在蛋白质工程和合成生物学领域,构建高质量的突变文库是筛选优良突变体的关键第一步。然而,很多研究者发现:用传统NNK/NNS简并引物构建的文库,明明设计时计算了完美的理论多样性,实际测序却出现严重的碱基偏好、终止密码子过多、氨基酸分布不均等问题。有没有一种方法,能真正做到“想要什么氨基酸,就等比例出现什么氨基酸”?
今天,我们就通过一个突变文库的真实案例,带你了解Trimer文库如何解决传统方法的痛点。文末更有Trimer引物7折活动,不容错过!
一.科普回顾:Trimer引物 vs 普通简并引物
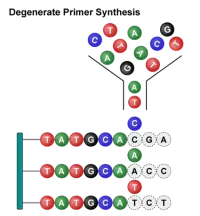
1.什么是简并引物?
简并引物是指在一管试剂中,混合了数十至数万种序列相近、但个别位置碱基不同的引物混合物。这些碱基可变的位点,称为简并位点。
最常见的简并方案是NNK(N=A/T/G/C,K=G/T)或NNS(S=C/G)。它们能编码全部20种氨基酸,但由于合成方式的限制,存在固有缺陷。
2.传统NNK引物的三大痛点
-
碱基偏好性:合成时单个碱基的偶联效率不同(A/C效率略高于G/T),导致最终引物池中32种密码子的实际摩尔比例严重不均。
-
终止密码子过多:NNK方案中终止密码子占比约9.4%,意味着近10%的克隆表达出截短蛋白,浪费筛选资源。
-
稀有密码子干扰:随机引入的密码子可能包含宿主(如大肠杆菌)几乎不使用的稀有密码子,导致突变体无法正常表达,造成假阴性。
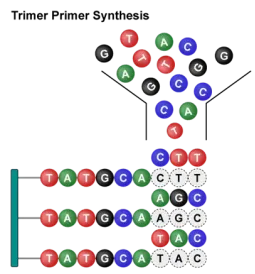
二.Trimer引物如何解决?
Trimer引物采用三核苷酸亚磷酰胺单体进行合成,每次添加一个完整的三碱基单元。由于所有三聚体模块的化学性质完全相同,在合成简并位点时,每一种密码子的偶联效率严格一致,最终实现:
-
真正的等摩尔比例:所有设计密码子理论拷贝数完全相同。
-
可剔除终止密码子:只选择编码20种氨基酸的密码子,无效克隆率降至0。
-
可定制宿主偏好:根据表达宿主的密码子使用偏好,只选用最优密码子,确保突变体高效表达。
三.什么是Trimer文库?
基于Trimer引物技术构建的突变文库,称为Trimer文库。它是目前公认的、在控制氨基酸组成和消除碱基偏好性方面最精准的文库构建方法。
1.消除碱基偏好性,实现真正的均衡
传统文库的问题:在合成NNK(N=A/T/G/C, K=G/T)时,由于4种碱基的化学偶联效率不同(通常A和C的耦合效率略高于G和T),导致最终合成的引物池中,32种密码子的实际摩尔比例并不相等。有些密码子占比很高,有些极低,导致筛选时遗漏重要突变。
Trimer文库的优势:由于三聚体模块的化学性质完全相同,它们以严格等摩尔的方式偶联。因此,最终文库中每一种设计好的密码子,其理论拷贝数完全相同,不存在偏向性。
2.精确控制氨基酸组成,避免终止密码子偏倚
传统文库的问题:最常用的NNK简并方案,虽然覆盖了全部20种氨基酸,但终止密码子(TAA, TAG, TGA)的比例很高。这意味着在筛选时,有接近10%的克隆是无效的(蛋白质截短)。如果使用NNS,同样包含终止密码子。
Trimer文库的优势:可以根据需求,剔除终止密码子。例如,可以定制一个只包含20种氨基酸密码子、且每种氨基酸出现频率相等的Trimer文库。这极大提高了有效文库的容量,减少了无效筛选的工作量。
3.消除稀有密码子
传统文库的问题:NNK随机引入的密码子,可能包含宿主细胞(如大肠杆菌)中几乎不使用的稀有密码子。这些稀有密码子会导致翻译速率下降、mRNA不稳定,使得一些本应有效的突变体无法正常表达,从而在筛选中被错误地判定为无效。
Trimer 文库的优势:可以根据表达宿主的密码子使用偏好进行定制。在合成Trimer文库时,可以指定只使用该宿主偏好的“最优密码子”来编码目标氨基酸,从而确保文库中的突变体在宿主中能够高效、稳定地表达。
四.Trimer文库应用场景
Trimer文库主要应用于需要高精度、高覆盖度、无偏好的场景:
-
蛋白质定向进化:
饱和突变:对某个关键位点或几个位点进行饱和突变,覆盖所有20种氨基酸。Trimer文库可以确保每个位点得到所有20种氨基酸,且比例均等,从而获得最全面的功能增益或减损突变体。
组合突变:同时对多个位点进行随机突变。Trimer文库可以精确控制突变组合的多样性,避免因偏好性导致某些组合丢失。
-
酶工程:
筛选具有更高活性、热稳定性或底物特异性的酶突变体。Trimer文库通过剔除终止子和稀有密码子,显著提高了有效文库的深度,使得在较小的筛选规模下就能覆盖更多的功能性突变。
-
合成生物学:
构建基因线路或生物传感器的突变库。当需要精确调控蛋白质表达水平或活性时,Trimer文库可以提供序列高度均一的变异体池。
-
抗体工程:
对抗体互补决定区(CDR)进行亲和力成熟。Trimer文库能够更均匀地引入氨基酸多样性,提高获得高亲和力变体的概率。
四.案例分享:库容超10亿的Trimer文库
我们分享的案例是客户希望构建一个噬菌体/酵母展示文库,用于筛选高亲和力结合蛋白。目标很明确,但设计要求却有一定难度:
-
突变区域:包含14个精确定义的简并位点(X1–X14),外加一段长度可变的区域(X15–Xn,n可以是23、26、29、32,对应9、12、15、18个连续简并位点)。
-
氨基酸比例定制:每个位点的氨基酸类型和比例不是简单的“全随机”,而是基于结构信息精细设计的。
-
理论库容:所有位点组合的理论多样性超过10⁹,是一个极高复杂度的文库。
面对这样的需求,Trimer 如何实现“精准定制”?
让我们用数据会说话
针对14个定制位点,我们通过Trimer技术精确实现了等比例与非等比例氨基酸设计;可变长度区域采用四种亚文库独立合成后等摩尔混合的策略;所有位点均剔除终止密码子并选用大肠杆菌偏好密码子,确保全长蛋白高效表达。
文库构建完成后,我们通过NGS深度测序进行了严格质控,结果显示:
3段 CDR 区组合正确率达61.05%!
-
在所有具备完整侧翼序列的Reads中,超过六成的突变区域完全符合设计——密码子、氨基酸、比例、长度,一个不差。在超高复杂度文库中,这个比例堪称“优等生”。
-
可变长度区域是这次设计的难点之一。四种不同长度的亚文库混合后,超过三分之二的Reads长度完全正确,说明Trimer模块在长片段合成中依然保持了优异的偶联均一性。
氨基酸分布:想要的比例,分毫不差
我们进一步分析了每个位点的氨基酸实际出现频率,结果与理论设计高度吻合:
-
等比例设计位点(如X1的8种氨基酸等比例):各氨基酸实测占比在理论值±1.2%范围内波动,没有出现NNK中常见的“某些氨基酸占比超10%、某些不足1%”的偏科现象。
-
可变区(X15–Xn):每个位点涵盖19种氨基酸(已剔除终止密码子),各氨基酸实测频率均在理论值(5.3%)附近,标准差小于0.7%,实现了均衡覆盖。

泓迅生物——Trimer文库&引物
泓迅生物领先设计和先进制造提供Trimer文库一站式解决方案,已成功交付了数百个高品质、定制化的突变文库。精准控制CDR区域的每个突变位点,调整氨基酸种类和比例,提升文库的准确度和实验的成功率。降低后期筛选难度,节省时间和精力,享受高性价比服务。
-
灵活定制服务
支持多位点突变与氨基酸比例定制,适配各类复杂文库构建需求。
-
精准控制氨基酸分布
氨基酸密码子比例控制精准且不受物种限制,方便客户设计与选择。
-
文库设计更精准
去除冗余和终止密码子,精准性更强,提升突变效率与文库有效性。
-
高覆盖、高均一性
引物覆盖度高、均一性优,显著增强文库多样性与实验成功率。
限时重磅福利:即日起至2026年4月30日,订购Trimer引物可享受7折优惠!

2026——为什么选择泓迅
领先的技术优势—AI赋能的合成生物学技术
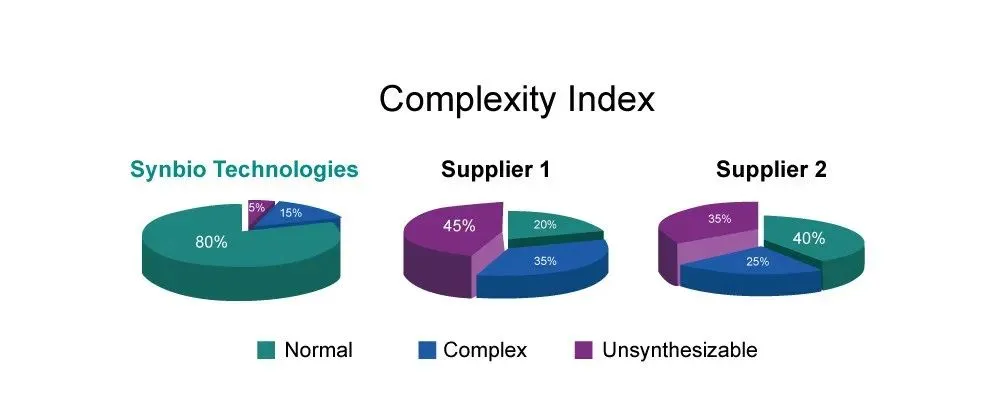
我们可以做—高难度的序列合成
更高的价值服务—一站式合成生物学解决方案