 Syno®C 引物合成
Syno®C 引物合成 RNA合成
RNA合成 mRNA合成
mRNA合成 Syno®GS 基因合成
Syno®GS 基因合成 载体构建
载体构建 高通量及DNA文库构建
高通量及DNA文库构建 CRISPR基因编辑平台
CRISPR基因编辑平台 病毒包装
病毒包装 基因测序与组学分析
基因测序与组学分析 重组蛋白表达平台
重组蛋白表达平台 抗体工程平台
抗体工程平台 多肽服务
多肽服务 生物信息学分析与设计
生物信息学分析与设计 CRISPR文库
CRISPR文库 合成生物学产品
合成生物学产品 ProXpress蛋白快速检测
ProXpress蛋白快速检测 CRISPR 质粒
CRISPR 质粒
Oligo Pools如何助力海量数据保存?
在当今的数字化时代,全球数据量正以惊人的速度增长,从社交媒体产生的海量内容,到医疗和科研中的数据,传统的数据存储方式已经面临存储密度、能耗和耐久性的极限。而DNA信息存储正逐渐成为一种备受关注的前沿技术。DNA天然具有极高的存储密度和稳定性,它不仅能够保存大量信息,还能在极端条件下稳定存在数千年。那么Oligo Pools(寡核苷酸池)如何支持数据存储技术的发展呢?
为什么选择DNA作为数据存储介质?
DNA是自然界中信息存储的最佳载体之一。在理论上,1克DNA可以存储超过200PB(千万亿字节)的数据,这样的存储密度远远超过传统的硬盘和蓝光光盘。并且,DNA的耐久性极高,在冷干环境中可以保存数千年,适合作为长期档案存储。此外,DNA存储几乎不消耗能源,能够大幅度减少现代数据中心的能耗需求,是实现绿色存储的理想选择。
Oligo Pools在DNA数据存储中的关键作用
Oligo Pools,即大量并行合成的短DNA序列集合,是DNA数据存储的核心支持技术。通过生成大量独特的DNA序列,Oligo Pools不仅为DNA存储提供了高效的编码方式,还解决了传统存储介质在容量、灵活性等方面的瓶颈。
1. 数据编码的“秘密武器”
在DNA存储中,数据首先要从二进制编码(0和1)转换为A、T、C、G的碱基序列。这一过程可以通过Oligo Pools来完成,将数据分割为小片段,然后合成成数以百万计的短DNA序列。每条寡核苷酸链代表一个数据片段,所有片段组合在一起形成完整的数据集。这一编码技术正是Oligo Pools的核心价值,使得DNA存储具备了在极小空间内保存海量数据的能力。
2. 完善的容错机制
DNA存储面临的一个主要挑战是误差管理。传统的数据存储系统通过冗余和校验技术确保数据完整性,而在DNA存储中,Oligo Pools通过增加冗余序列和纠错机制来解决这一问题。研究显示,通过组合PCR等技术,科学家们能够在读取过程中排除非目标序列,从而实现99.9%以上的检索精度。这种技术不仅适用于DNA存储,还可以帮助合成基因片段或数据文件,为未来的基因组编辑和数据修复提供重要支持。
3. 高效的数据检索能力
存储数据的目的是为了有效的读取和利用。在DNA数据存储中,读取过程主要依靠DNA测序,而Oligo Pools能够实现特定序列的靶向检索,使得数据提取更加高效。例如,通过设计独特的引物序列,科学家可以在一个复杂的DNA池中选择性地检索出特定数据,避免了不必要的测序资源浪费。这一高效的检索能力不仅提升了DNA存储的实际应用价值,也为高通量的科学研究提供了便利。
如何利用Oligo Pools进行数据存储?
• 选择合适的编码策略
DNA存储的密度和误差率受编码方式影响很大。泓迅生物具备灵活的编码方案,能够帮助优化数据存储效率和准确性,确保数据存储的稳定性。
• 保持良好的存储环境
虽然DNA具有很强的稳定性,但冷、干燥、避光的存储环境能够延长其保存期限,确保数据在长期内不受损失。
• 注重规模化生产
随着数据存储需求的增长,高通量的Oligo Pools合成显得尤为重要。泓迅生物拥有丰富的专业经验,可以确保大规模数据存储的可靠性和可扩展性。
如何支持DNA存储成为主流?
随着Oligo Pools和组合PCR等技术的不断发展,DNA存储正逐渐从理论走向实践,并有望成为未来主流的数据存储方式之一。 Oligo Pools为DNA数据存储提供了高效、可靠的数据编码、存储和检索解决方案。
通过Oligo Pools,DNA存储不仅能够实现超高密度,还能确保长期的稳定性,打破了传统存储方式的诸多限制。可以预见,Oligo Pools将随着DNA存储的进一步发展,不断扩展应用,甚至可能会被应用于数据中心、医院档案和公共记录等长久保存需求极高的场景。
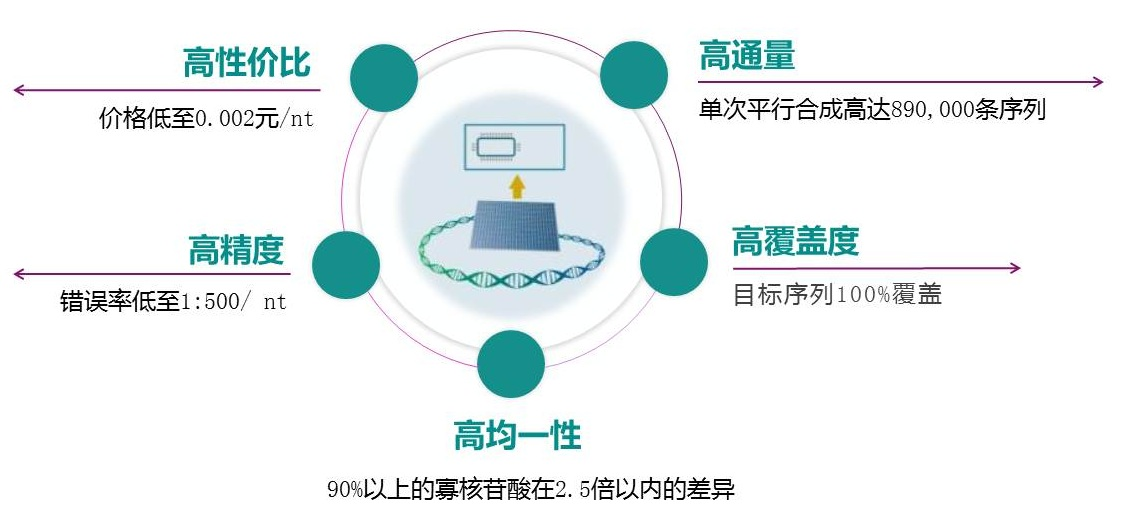
泓迅生物Syno®高通量合成平台利用喷墨技术在芯片上单次平行合成高达89万条寡核苷酸序列,最长可达300 nt。在合成过程中,每个反应位点形成彼此隔离的微液滴,保障零交叉污染,合成的序列准确性高、均一性好。定制化合成服务可完美匹配客户下游实验和应用。如CRISPR sgRNA筛选文库、高通量测序、高通量基因合成、合成生物学等,提高后续高通量筛选效率和长片段组装成功率。
References
Winston, C., Organick, L., Ward, D., Ceze, L., Strauss, K., & Chen, Y. J. (2022). Combinatorial PCR method for efficient, selective oligo retrieval from complex oligo pools. ACS Synthetic Biology, 11(5), 1727-1734.


























